paperswithcode : https://paperswithcode.com/paper/vitpose-simple-vision-transformer-baselines
Papers with Code - ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
🏆 SOTA for Pose Estimation on COCO test-dev (AP metric)
paperswithcode.com
오늘은 ViTPose 라는 pose estimation 논문에 대해 읽어 보았다
이전에 코드를 사용한 적은 있는데, 논문을 제대로 읽어보지 못했기 때문에 이번 기회에 다시 한번 읽어 보았다
Abstract
vision transformer 가 pose task 에 대해서도 많이 사용되고 있는데, 다들 CNN backbone 을 사용하여 feature 를 추출하거나 굉장히 신중하게 transformer 를 구상하여 모델을 만들고 연구한다
하지만 이 논문에서는 plain 한 기본적인 transformer 구조로 성능이 어느정도 잘 나올까 하는 발상을 통해 아주 단순하면서도 효과적인 ViTPose 를 제안했다
VitPose 는 모델 구조가 단순하면서, 모델 크기의 확장성도 좋고 여러 유연성을 가지고 있으며 특히 sota 를 달성할 정도로 성능도 매우 좋다고 한다
Introduction
사람의 포즈 추정 문제는 computer vision 의 주요 task 이고, real world 에서 응용 분야가 다양하다
포즈 추정이라 함은 사람의 해부학적은 키포인트(어깨, 팔꿈치, 손, 무릎 등..) 의 위치를 찾는 것이다
vision transformer 가 활발히 연구됨에 따라 encoder, decoder 를 통합한 PRTR, encoder 와 CNN 을 사용한 TokenPose,TransPose 등 여러 연구에서 transformer 를 이용한 포즈 추정 연구가 활발하다
하지만 abstract 에서 말했듯 다들 복잡한 구조, 계층 등을 사용한다
이 논문에서는 역으로 기본적이고 간단한 vision transformer 로 포즈 추정을 하려고 한다
그렇게 만들어진 것이 ViTPose 이다
VitPose 는 기본적이고 비계층적인 vision transformer 를 backbone 으로 사용하여 person instance 에 대한 feature 를 추출했고, 이 backbone 은 데이터셋에 MAE 라는 masked autoencoder 방식을 적용 후 pretrain 하여 좋은 initialization 을 했다
또한 경량 decoder 를 사용하였다
단순히 몇개의 transform layer 를 staking 하는 것으로 encoder 구조를 얻을 수 있어서 특별한 domain 지식이 필요하지도 않다
구조적으로 단순하기 때문에 병렬성도 가질 수 있어 추론 속도나 성능을 더욱 높여주고, 모델 사이즈의 확장성, 유연성 등 여러 이점을 가지게 되었다
결국 이 논문에서 말하고 싶은 것은 세가지 라고 한다
1. 사람 포즈 추정을 위한 ViTPose 라는 아주 단순하면서 효과적인 baseline 모델을 제시했고, MS COCO 에서 sota 성능을 달성
2. ViTPose 는 구조적 단순성, 모델 사이즈 확장성, 유연성, 지식 전달성 등 여러 뛰어난 장점들이 있음을 입증
3. benchmark 에서는 매우 큰 backbone 을 넣으면 MS COCO 에서 최고의 성능을 얻음
Related Work
ViT 의 성공에 따라 vision transformer 를 이용한 연구들이 많았고 보통 ImageNet 1K 를 이용한 fully supervised 로 pretrain 하였다
ImageNet 은 크고 pose 외의 정보들 때문에 사용하기 단순하지 않아서 논문에서는 masked image modeling 을 적용한 더 적은 unlabel 데이터셋을 이용하여 pretrain 해보았는데 좋은 initialization 을 얻었다고 한다
VitPose
The simplicity of ViTPose
Structure simplicity
논문에서는 구조가 단순하면서 성능은 높이기 위해 복잡한 모듈은 최대한 피했다
결국 transformer backbone 뒤에 몇개의 decoder layer 만 추가하여 heatmaps keypoints 를 얻도록 했다
단순성을 위해 decoder 에 skip-connection 이나 cross-attention 은 적용하지 않고 deconvolution layer 와 prediction layer만 적용했다(classic decoder 기준, decoder 전략은 뒤에서 더 자세히)
모델의 input 이 거치는 과정을 간략히 보자면
1. patch embedding layer 를 통해 input image 에 대한 embedding 을 추출
2. embedded tokens 는 multi-head self-attention(MHSA) layer 와 feed-forward network(FFN) 으로 구성된 몇개의 transformer layer 를 통과
3. decoder 를 통해 predict
구조는 다음과 같다
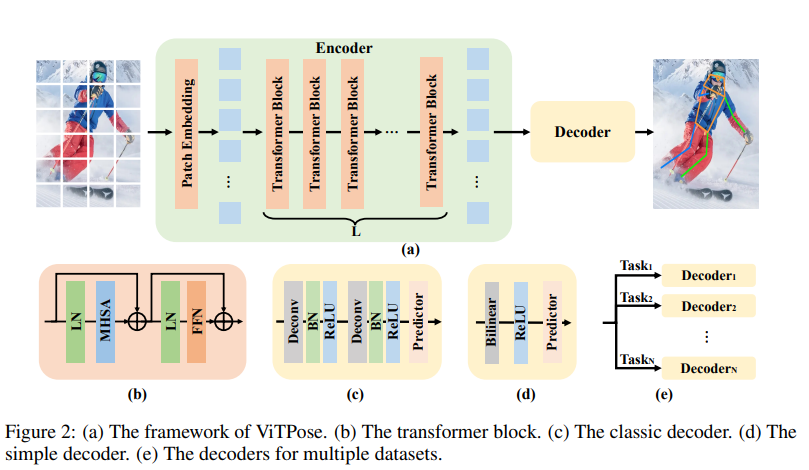
위에서 보듯이 decoder 형태는 2가지가 있다
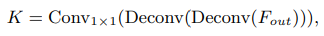
우선 classic decoder(c) 는 2개의 convolution blocks 이며 각 block 은 1개의 deconvolution layer 에 batch normalization 과 ReLU 가 붙는 구조이고, 각 block 은 feature map 을 2배 upsample 한다
( torch.nn.ConvTranspose2d(model,model,2,2) / torch.nn.BatchNorm2d(model) / torch.nn.ReLU() )
그 후 kernel size 가 1x1 인 conv layer 로 keypoints 를 위한 localization heatmaps 을 얻는다
(torch.nn.Conv2d(model,output_channel,1,1 )
classic decoder 도 경량하지만 더 경량한 decoder 도 구상하였다
simple decoder(d) 는 bilinear interpolation 을 이용하여 feature maps 을 4배 upsample 하고 ReLU 를 붙였다
( torch.nn.Upsample(scale_factor=4,'bilinear'), torch.nn.ReLU )
그리고 3x3 kernel size 의 convolution layer 를 이용하여 heatmaps 를 얻었다
( torch.nn.Conv2d(model, output_channel,3,3 )
The scalability of VitPose
앞서 보았듯 ViTPose 는 구조가 단순하여 다양한 수의 transformer layer 를 쌓거나 feature dimension 을 줄이거나 늘려서 모델 사이즈를 조절할 수 있다
또한 모델 크기 증가에 따른 일관적인 성능 향상이 있다고 한다
The flexibility of VitPose
Pre-training data flexibility
: ImageNet 이 아닌 MS COCO, AI Challenger 에 MAE(masked Auto Encoder)를 적용하여 backbone network 를 초기화함
: ImageNet 보다 훨씬 작은 데이터를 이용했음에도 좋은 initialization 을 학습 할 수 있음을 보임
Resolution flexibility
: input image 의 해상도를 높이려면 image size 만 조정하면 됨
: feature 의 해상도를 높이기 위해 downsampling ratio 를 낮추려면 patch embedding layer 의 stride 만 변경 하면 됨
Attention type flexibility
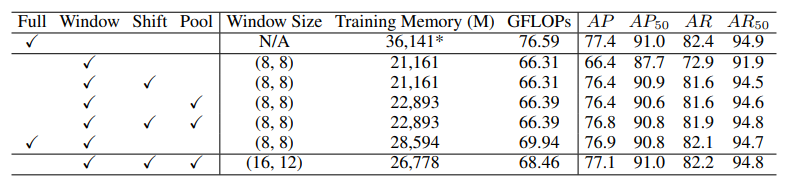
: full attention 은 계산 비용이 너무 많이 듬
: window attention 은 계산 비용은 덜하나, 단순히 모든 transformer blocks 에 사용시 성능이 떨어짐
: 두가지 attention 전략 사용
1) shift window attention : 고정된 window 가 아닌 shift window 방식을 사용하여 window communication
2) pooling window attention : window 에 pooling 을 하여 window communication
: 위 전략 중 하나를 사용하거나 특히 함께 사용했을때는 성능 개선이 높고, 계산 비용도 많이 줄었음을 입증
Finetuning flexibility
: NLP 에서는 pretrained 한 transformer models 이 부분적으로 finetune 했을때 다른 task 에 일반화가 잘된다고 함
: unfrozen, MHSA frozen, FFN frozen 세가지 세팅으로 finetune 을 해보니 MHSA frozen 시 전체를 finetune 한것과 유사한 성능을 보임
Text flexibility
: VitPose의 decoder 가 매우 단순하고 가볍기 때문에 동일한 encoder 를 사용하여 많은 추가 비용 없이 multi pose task 도 할 수 있음
The transferability of ViTPose
보통 더 작은 모델의 성능을 개선하는 방법 중 하나는 큰 모델로 부터 knowledge distillation 하는 것 이다
teacher network T 와 student network S 가 주어지면
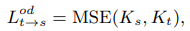
간단한 distillation 방식은 끝에 distillation loss 를 추가하여 student network output 이 teacher network output 과 비슷하게 나오도록 하는 것
이 논문에서는 위 방법을 보완하여 large 모델과 small 모델을 연결하는 token-based distillation 을 적용했다
이때 knowledge token 이 필요한데 이것을 만드는 과정을 보자면 아래와 같다
1. 학습 가능한 knowledge token t 를 랜덤하게 초기화
2. teacher model 의 patch embedding layer 이후 기존 visual tokens 에 knowledge token t 를 추가(append)
3. 잘 학습된 teacher model 을 freeze 하고 몇 epoch 동안 knowledge token 만 학습
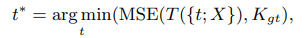
Kgt 는 heatmaps 의 groud truth
X 는 input images
T 는 teacher 의 predictions
t* 은 loss 를 최소화 하기위한 optimal token
그 후 학습된 knowldege token t* 는 freeze 하고 student network 의 visual tokens 와 concat 하여 학습 한다
이때 사용하는 최종 distillation loss 는 아래와 같다
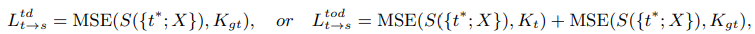
Ltd 는 token distillation loss
Ltod 는 token distillation loss 와 output distillation loss 를 합한 것
최종적으로는 Ltod 를 사용했다고 한다

ViTPose-L 을 teacher 로 하여 ViTPose-B 를 MS COCO 에 대해 knowledge distillation 한 것이다
token distillation loss + output distillation loss 일때 확실히 성능이 높아진 것을 확인할 수 있다
Conclusion
vision transformer 기반의 사람 포즈 추정을 위한 단순한 ViTPose 를 소개했다
단순성, 확장성, 유연성, 전달성 등을 입증하였고 sota 성능을 달성하며 효과를 보여주었다
오늘은 pose estimation 에 대한 논문을 읽어보았다
코드는 이전에 이용해본적이 있었는데 결과물이 다른 모델들에 비해 상당히 좋았던 걸로 기억한다
transformer, attention 쪽은 주로 공부하지 않았어서 논문을 보면서 중간 중간 계속 찾아보며 읽게 되었지만 논문 자체 아이디어가 간단한 모델 구조의 효과에 대한 것이라 그런지 매우 쉽게 읽혔다
보통 새로운 모델을 만들때 새로운 구조, 어떤것을 더 넣을지 등을 많이 생각하는 것 같은데 여기선 오히려 더 단순하고 기본적인 구조를 이용했는데 성능도 좋고 여러 이점을 가지는 것이 신기하고 재미있었다
특히 distillation 에서 token 을 이용하는 부분이 나는 처음 보는 방식이라 참신하게 느껴졌다
앞으로 transformer, attention 에 관한 다른 논문들도 많이 보고 싶어졌다
