kakao enterprise ai reseach 에서 papers 를 보다가 발견한 논문
https://kakaoenterprise.github.io/papers/aaai-debiasing
Revisiting the Importance of Amplifying Bias for Debiasing
Abstract
kakaoenterprise.github.io
이전 얼굴 이미지 데이터셋을 이용했을때도 항상 배경이나, 헤어스타일, 악세사리 등 편향적 특성이 강하게 나타나면 학습에 악영향을 끼치는 경우가 많았다
이런 경우를 위해 Debiasing 을 하는데 , 이 논문은 2022 에 발표된 논문으로 debiasing 성능을 개선하기 위한 새로운 접근법을 보여주고 있다

Abstract
debiasing 은 데이터셋의 bias 에 대해 덜 민감한 classifier 를 학습하기 위한 것 이다
데이터셋의 bias 라 함은 예를 들어 만약 개구리가 target 일때 개구리 이미지는 주로 늪을 배경으로 한 경우가 많다
이때 늪배경을 bias attribute 라고 하고 debiased classifier 라면 해변에 있는 개구리 이미지라도 개구리라고 잘 분류를 해야 한다!
이때 개구리가 늪에 있는 이미지 처럼 bias 와 intrinsic sample 간 상관관계가 높은, 자주 나타나는 데이터를 bias aligned 라고 하고,
개구리가 해변에 있는 것 처럼 상관관계가 낮은 데이터를 bias conflicting 이라고 한다!
최근 연구에서는 debiasing 을 위해 biased model 과 debiased model 두개를 같이 사용한다고 한다
편향에 과적합 된 biased model 'fB' 가 있으면 fB 가 학습하지 못한 샘플에 집중하여 debiased model 인 'fD'를 학습하는 것!
이렇게 최근 연구들은 debiased model fD 에 중점을 두었다면, 여기서는 biased model fB 에 중점을 두었다
fD 의 성능이 상승하려면 fB의 training set 에서 bias conflicting samples 를 제거하는 것이 중요하다는 것을 분석하여 알게 되었다고 한다
왜냐면 bias conflicting samples 가 bias 에 overfit 한 모델을 만드는데 조금이라도 들어가면 noisy 한 역할을 해서 악영향을 끼친다고 한다
따라서, fB 를 위한 bias amplified datasets 을 만들기 위해 효과적이고 간단한 data samples 선택 방법을 제안한다!
이 방법은 기존 다른 debiasing 방식에도 적용 가능하며, real 이나 synthetic data 모두에서 sota 성능을 달성한다고 한다!
Introduction
데이터셋의 대부분에 편향(bias) 이 있는 경우 image classification model 은 이러한 bias 에 의존할 수 있다
그리고 bias 는 보통 target class 와 함께 발생한다
앞에서 말했듯, 개구리는 보통 늪에 있는 이미지가 많으나 해변이나 풀숲에 있을 수도 있다
이런 경우 모델이 bias 에 의존하게 되면 늪을 단서로 하여 개구리라고 분류할 수 도 있고, 다른 장소의 개구리는 개구리라고 분류하지 못할 수도 있다
이러한 문제를 완화하려면 image classification 을 위한 debiasing 은 개구리의 다리나 눈과 같은 target class 의 시각적으로 intrinsic(본질적인) attributes 에 중점을 두어야 한다
하지만 biased datasets 에서는 bias aligned sample 보다 bias conflicting sample 이 지나치게 부족하다
이러한 부족 때문에 존재하는 debiasing 에 대한 sota 연구들은 bias conflicting sample 에 high weight 을 주고 bias aligned sample 에 low weight 를 주는 reweighting 을 적용하여 학습한다!
2020 Learning from Failure: Training Debiased Classifier from Biased Classifier 연구에서는 bias attribute 가 아무래도 intrinsic attribute 보다 학습되어지기 쉽기 때문에 이를 이용하여 reweight 하였다고 한다
구체적으로 말하자면, 고의적으로 bias overfit 하도록 fB를 학습하고 이것을 이용하여 구별한 후 reweight 하는 것이다
결과적으로 fD 의 debiasing 성능을 올리기 위해서는 fB 가 얼마나 bias attribute 에 overfit 되어 있느냐가 중요한 것이다
하지만 이 논문에서는 이전의 reweighting 을 위한 fB 가 bias attribute 를 최대한 활용하지 못했다고 한다
reweighting 시 bias aligned sampled 에 overfit 하기 위해 loss function 까지 고안하여 사용했으나, fB 를 학습할때 사용한 데이터셋에 조금의 bias conflicting samples 가 noisy 하게 작용하여 방해가 되었다고 한다
이러한 문제들 속에서도 이전 연구들에서는 bias conflicting samples 를 제거하는 것에 중점을 두지 않았다
이 논문에서는 이 부분에 집중하여 fB 를 제대로 bias overfit 하게 학습 할 수 있도록 '간단하면서도 효과적인' bias amplified samples 를 만들기 위한 sample 선택방법을 제시 한다
즉 bias conflicting samples 를 제거하여 정제하는 방법을 제시한 것 이다
우선 bias attributes 는 학습하기에는 쉽지만, 다양한 시각적 attributes 를 포함한다
예를 들어, 사람 얼굴 이미지에서는 헤어스타일이나, 메이크업 등 을 의미한다
하나의 biased model 이 biased prediction 을 하기 위해 이러한 다양한 시각적 속성을 포괄적으로 고려하는것은 어렵다

위의 fig1 은 서로 다르게 random initialized 한 같은 모델을 잠깐 학습 했을때 모델이 집중하는 부분을 visualization 한 결과이다
열마다 (f*Bn) 다른 initialized 이다
같은 모델 임에도 불구하고, 각자 중점적으로 보고 있는 부분이 다르다는 것을 확인할 수 있다 (입술, 머리카락, 얼굴 등)
이전 연구들 에서도 dnn 을 서로 다르게 random initialized 하면 다른 방식으로 학습된다는 결과가 있다고 한다
이러한 부분은 결국 다양한 biased model predictions 을 이용해야 다양한 시각적인 bias attributes 를 포착할 수 있다는 것을 의미한다
여기서 제안하는 방식은 간단히 다음과 같다
1. bias 의 다양한 시각적 attributes 를 포착하기 위해 서로 다른 random initialized biased model 을 적은 수의 iteration 동안 pretrain 한다 ( bias attribute 는 초기 만으로 학습이 된다는 연구가 있기 때문 )
2. 서로 다르게 학습된 biased model 의 predictions 를 이용해서 bias conflicting samples 를 제거하여 더 정교한 biased amplified samples 을 만든다
3. 정제된 데이터셋으로 fB 를 학습한다
4. 학습한 fB 를 이용하여 fD 학습에 이용한다
이전 reweighting 연구들에서는 간과 되었던, 얼마나 fB가 bias 에 overfit 되어있느냐가 fD 의 debiasing 성능에 크게 영향을 끼친다는 것을 알게 되었고, fB 를 위한 데이터셋의 정제에 대해 중점을 두었다
Related Work
debiasing 에 대한 초기 연구들은 training 동안 bias label 을 명시하거나 bias type 을 암묵적으로 미리 정의 하였다
하지만 이러한 작업을 하기 위해서는
1. 주어진 데이터셋의 bias type 을 사람이 식별해야 함
2. 알지 못하는 bias types 에 대한 debiasing 성능에 제한이 있음
이라는 문제가 있었다
그래서 최근에는 reweighting 에 대한 방법들이 많이 나오고 있다
Importance of Amplifying Bias
Background
overfitting model to the bias
앞서 말했듯이 bias label 명시나 bias types 의 정의 작업은 어렵기 때문에 최근엔 그러한 정보가 필요없는 Generalized Cross Entropy(GCE) 를 활용 했다
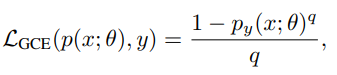
q 는 amplificaiton 의 강도를 조절할 scalar value
p(x;θ), p(y;θ) 는 softmax output
y 는 target class 의 softmax probability 이다
GCE 는 target class 에서 높은 probability 를 가지는 sample 의 gradient 에 high weight 를 할당한다
따라서 biased model 기준 high probability 를 가지는 bias aligned sample 에 중점을 두도록 한 것이다
Reweighting-based approaches
최근 sota debiasing 방식들은 biased model fB 와 debiased model fD 를 이용하여 reweight 하는 방식이다
fB 는 bias attributes 에 overfit 하게 학습 후 이것으로 reweight 하면서 fD 를 학습하는 것이다
fB 는 bias 에 매우 의존적일 것이므로 bias conflicting samples 에 대해서는 제대로 classify 못하므로 Cross Entropy loss 를 쓰는데 loss 값이 bias aligned samples 에 비해 bias conflicting samples 가 high 할 것 이라는 점을 이용한다
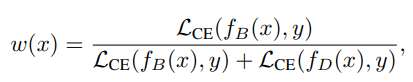
fB(x) 와 fD(x)는 각 fB, fD 모델의 prediction output
y 는 sample x 에 대한 target label
결국 bias conflicting samples 에 대한 weight 는 high 해지고, bias aligned sample 에 대한 weight 는 low 해져서 fD 의 debiasing 성능을 올리는 것이다
따라서 fB 가 얼마나 bias attribute 에 overfit 한지가 fD 의 debiasing 성능에 큰 영향을 끼친다는 것을 알 수 있다
Revisiting fB in Debiasing Methods
GCE loss 를 사용한 모델의 성능이 아쉽다고 했었는데, 그것에 대해 분석하려고 한다
실험에서 이 분석이 real 과 synthetic 데이터에서 모두 적용가능하다는 것을 보여주기 위해 colored MNIST 와 biased FFHQ 데이터셋을 사용했다
또한 training set 에서 bias conflicting samples 는 1% 만을 차지한다
Imperfectly biased
fB 가 완전히 bias 에 overfit 하다면 biased test set 에 대해서는 높은 정확도를 가지고, 그 반대에선 낮은 정확도를 가져야 한다
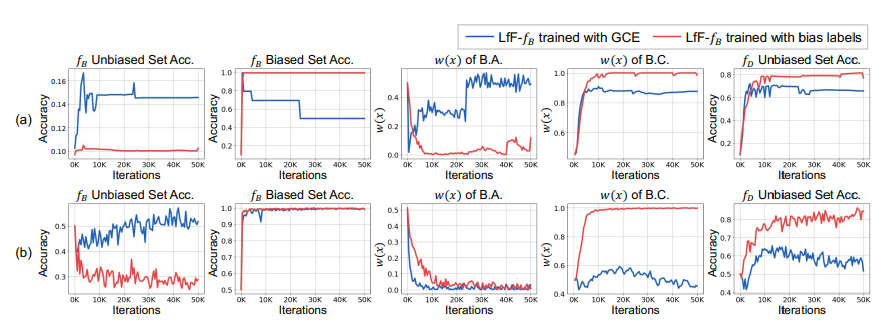
(a) 는 colored MNIST, (b) 는 biased FFHQ
파랑색은 GCE 로 학습된 모델이며, 빨강색은 bias label 을 명시하여 CE 로 학습한 모델이다
1열과 2열의 그래프를 보면 GCE 로 학습된 모델 fB 는 unbiased set 에서 정확도가 상대적으로 높고, biased set 에서는 상대적으로 낮은것을 볼 수 있다
따라서 제대로 bias overfit 이 되지 않았다는 것이다 또한 1% 만 있어도 overfit 학습에 악영향을 끼친다는 것이다
Debiasing fD via fB
reweighting value w(x) 는 학습 중에 sample x 에 fD 모델이 얼마나 중점을 두어야 하는지 결정한다
이것은 bias conflicting samples 는 high w(x) 를 가지고 반대는 low w(x) 를 가지는 두 조건을 동시에 만족하는 것이 중요하다
즉 debiasing performance 를 높이기 위해서는 이 두 w(x) 의 차이가 커야한다
figure 2 의 3열과 4열을 보면 GCE 로 학습한 모델은 상대적으로 biased aligned sample(B.A.) 에서 w(x)가 높고 bias conflicting sample(B.C.) 에서는 w(x)가 낮은것을 볼 수 있다
Debiasing with Bias-Amplified Dataset
Detecting Bias-conflicting Samples
결국 적은 수의 bias conflicting samples 라도 biased overfit 학습에 악영향을 끼치므로 그것을 버리고 bias amplified datasets 을 구축해야 한다
이것을 위해 GCE loss를 이용하여 적은 수의 iteration 동안 biased model 들을 pretrain 한다 ( 초기 학습동안 잘 학습 되기 때문에 짧게 학습)
학습된 biased model 은 결국 bias aligned samples 에서 target class 에 대해 high confidence 를 가질 것이고 bias conflicting samples 에 대해서는 low confidence 를 가질 것!
target class 'py' 의 probability 를 이용한 bias confilicting detector (BCD) 를 다음과 같이 정의 하였다

τ 는 confidence threshold
따라서 threshold 보다 confidence 가 같거나 높으면 (bias aligned sample) bcd 값은 1 이고 , 반대의 경우 0 의 값을 가진다
biased pretrined 모델의 예측으로 BCD 값을 얻어 데이터셋을 정제하고, 이것으로 fB 를 학습하는 것이다
그 후 fB 를 이용하여 fD 를 학습하는 것!
Improving Detection via Multiple BCDs


앞서 소개한 BCD 를 single 로 써도 성능이 개선되었다
하지만 introduction 에서도 말했듯, bias attribute 에는 다양한 시각적 attribute 가 존재한다
또한 앞에서 보았듯, random initialized 모델들은 각각 다른 특성들을 중점적으로 학습하는 것을 보았다
따라서 이런 부분에서 성능에 차이를 일으킬 수 있을거라 생각했다
이것에 대한 해결법 중 하나는 모든 bias attribute 를 고려하는 것!
그러기 위해서 multi BCD 를 이용할 것이다!
이것을 BiasEnsemble(BE) 라고 이름을 붙였다,
위의 테이블에서도 보이듯이 (M 은 BCD 의 갯수) multiple 일때 더 좋은 성능을 보인다
결국 multi BCD 의 값에 의해서 데이터셋이 정제 되어지며, 이때 BCD 의 대부분이 conflicting 이라고 결정하면 그것은 conflicting 으로 간주되어 버리게 된다

위와 같이 PBA 에 따라 multiple BCD 를 거친 sample 의 작업이 결정되는 것이다
BCD=1 이면 biased aligned sample 이고 0 이면 biased conflicting sample 이므로, BCD 갯수 M 중 반보다 크거나 같은 만큼이 1이라면 PBA 가 1의 값을 가지므로 bias aligned sample 이라고 결정하고 반대는 0 이 되어 bias conflicting 이라고 결정 지어 지며 제거 된다
multiple BCD 는 짧은 iteration 동안만 학습하여 추가적인 계산 비용이 적으며, 모두 같은 구조이기 때문에 메모리 공간 절약을 더 하기 위해 반복적으로 다시 initialized 하면서 학습한다고 한다
Training Debiased Model Using DA
결국 과정을 간략히 정리하자면
1) bias conflicting samples 가 섞인 기존 데이터셋 D를 이용하여 random initialized 한 biased model 을 짧은 iteration 동안 학습하여 여러 bias attribute 에 대해 학습한 모델을 얻는다
2) 이 모델을 이용하여 datasets 을 정제하는데, predictions 를 PBA 에 적용하여 bias conflicting sample 을 인식하고 제거한다
3) 정제된 bias amplified samples 를 이용하여 fB 를 bias 에 아주 overfit 하도록 학습 한다
4) fB 를 이용하여 reweighting 으로 fD 를 학습하여 debiasing 성능이 높은 모델을 얻는다
과 같다
이때 1) 에서의 biased model 에서는 GCE loss 를 사용하고 3), 4) 의 fB, fD 에서는 CE loss 를 사용한다
Conclusion
bias attribute 를 최대로 활용하여 fB 를 학습하기 위한 biased sample 선택 방법인 BiasEnsemble 을 제안했다
메인 finding 은 이전 debiasing 연구들이 간과한 "얼마나 fB가 bias 에 잘 overfit 되었는지가 fD의 debiasing 성능에 영향을 크게 미친다는 것" 이었다
bias 에 overfit 하게 학습하는 동안 bias conflicting samples 이 학습을 방해하였고, 그것을 bias amplified samples 로 정제하기 위해 BiasEnsemble 을 사용하여 filtering 하였다
다양한 시각적 특성을 고려하기 위해 BiasEnsemble 은 multiple 한 BCD 모델로 이루어진다
이러한 단순한 접근이 최근 reweighting 기반의 debiasing 성능을 개선하였고, synthetic 한 데이터 뿐 아니라 real world 데이터 에서도 적용 가능하고 sota 성능을 보인다
fD 에 비해 상대적으로 간과되어온 fB 에 중점을 두었고, 이러한 점이 debiasing 에 대한 향후 연구들에도 insight 한 발견을 줄 것 이라고 생각한다
딥러닝 학습에 있어서 데이터셋의 정제는 계속 가져가야하는 문제 인것 같다
인식에서 빼놓을 수 없는 bias 에 대해 정말 간단한 접근, 적은 computing cost 로 효과적인 데이터셋 정제를 하였고 결과적으로도 좋은 sota 성능을 달성했다는 것이 흥미로웠다
얼굴인식을 위해 open dataset 을 쓰거나, crawling 하여 데이터를 모아두면 확실히 나이대, 성별, 인종 마다 편향적인 특성들이 참 잘 보인다 (머리 색, 머리 길이, 화장, 악세사리 등)
예전에 이런 부분에 대해 크게 해결법을 적용하지 못했었는데, reweighting 이라는 방식도 함께 알게 되면서 그것보다 더 성능을 높일 수 있지만 간단한 접근법을 알게 되어서 좋았다
다음에 인식 모델을 만든다면 이러한 방법을 한번 적용해보고 싶다
